Incident Command System 101

By Urban Jurca, System Operations Division Lead at Bitstamp
Preface
It has been a crazy ride in crypto space for the last couple of months. Every crypto service provider is seeing unprecedented levels of interest and demand for its services. User registrations are soaring, trading volumes are topping record levels, every pipeline in production is registering new performance tops and so is the amount of traffic hitting all services. It is amazing what a capable platform can do, however no matter how great a platform, you will always run into some blips along the way. Some can be very mundane such as excessive logging eating up storage resources, some can be very "interesting" such as a matching engine going down.
These glitches will always occur and are a natural part of running any platform. Most of them do not affect any customer facing services and can usually be handled during office hours or by engineers on call. Some blips can however quickly turn into full scale production incidents that can easily directly affect the customers' experience. These incidents usually require more than a handful of engineers resolving them and without any response framework in place they quickly turn into a mess as everyone is solving everything and shouting (in pre-covid times) across the room. In the early years we had our share of messes and agreed that a better system is needed to manage resolvers and communication during such incidents. What follows is our Incident Command System.
Incident Command System - High Level Overview
The following is our ICS on June 2021. We have very honest retrospectives after each time it is used and adapt it accordingly if it failed in some particular area. If you take it as a template, it might not work 1:1 for you and you should simplify it as much as you can.
In our parts of the world the best teams by far in leading and coordinating most emergencies are firemen / fire departments. The same is usually applied to other corners of the globe and one of the best systems for handling emergency situations was developed by California's Fire Department and is described here: Firescope
So why did we adopt our own version if everything is already defined? Did we reinvent the wheel? Well... this is the organizational structure as defined in the original document:
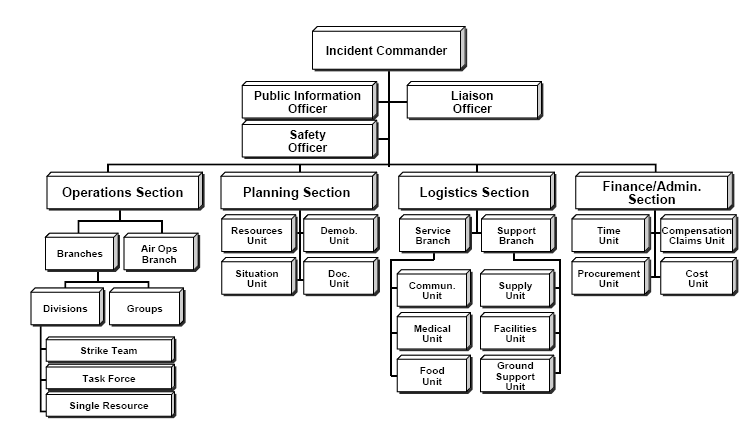
Most computer (cloud / software / ...) related incidents do not require such framework overhead and since we are operating in the financial industry and need to resolve incidents fast, setting something like this up takes too much time. So we simplified the original and streamlined it. The end result is something like this:
Whenever an incident is taking place we define the following roles and functions:
Incident Commander - IC
- This is the first and only mandatory role to exist during an incident. It is assumed automatically by the first responder.
- The IC is in charge of the incident (has decision power) and holds all high-level information about it.
- The IC assumes all roles (operations, communications, planning) until the IC delegates the roles forward.
- The first responder is usually not best fit for the IC role and a handoff should be made if a more suited responder joins the incident.
Operations Lead - OL
- The OL and responders under the OL are responsible for making production changes. No one else touches the systems.
- All actions taken by OL are documented under a command post.
- Usually multiple teams are created under the OL, e.g. database team, frontend team, infrastructure team, and they should compartmentalize their tasks and report back to the OL. We call this role split and fan out.
Communications Lead - CL
- Responsible for internal and external communication - stakeholder updates, status page updates.
- The CL is also responsible for keeping incident state documents up to date. Usually this calls for multiple scribes documenting each team under the OL and IC decisions.
- The CL updates new responders joining the incident or directs them to state documents.
Planning Lead - PL
- Should support other leads when necessary.
- Responsible for bringing in new responders to an incident.
- We are deprecating this role in the future as we found it redundant for our use case. However, should you have long lasting incidents it might come in handy.
Command Post - CP
- Predefined communication channels where teams communicate - Zoom rooms, Slack channels, etc.
- Always prefer text over voice, as it will generally bring greater order to problem resolving.
Incident State Documents - ISDs
- We use predefined Confluence pages where we consolidate the state of the incident.
- All scribes under the CL put their notes here.
- New resolvers joining the incident can use ISDs to get up to speed and not interfere with ongoing activities.
Incident Command System in Practice
The main idea behind our ICS is that it should be flexible and streamlined as much as possible. While the above described roles are mandatory with every incident, we take great care that they do not hinder active problem solving. Within the ICS these roles can be switched, handed over and compartmented as we see fit during an incident. How this works is illustrated below.
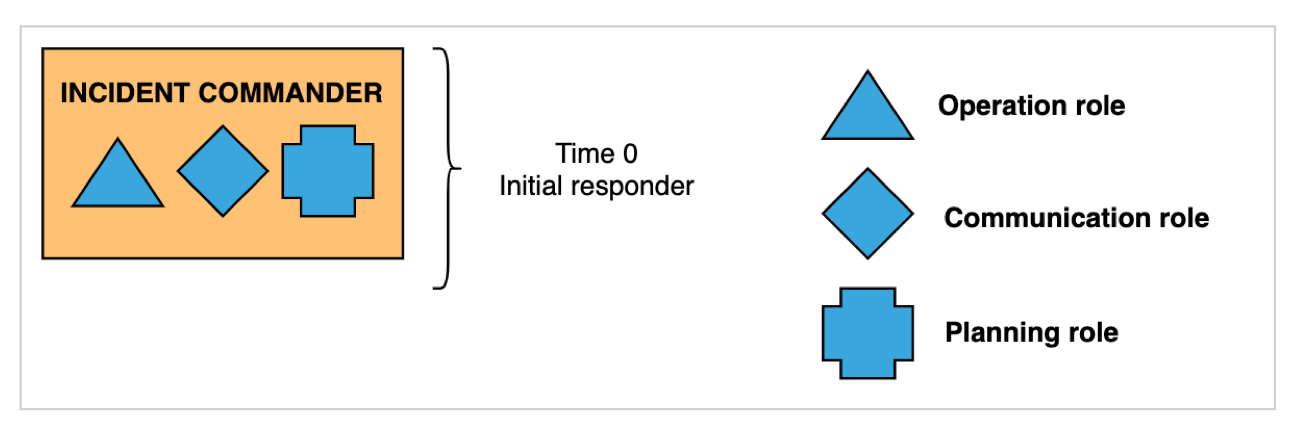
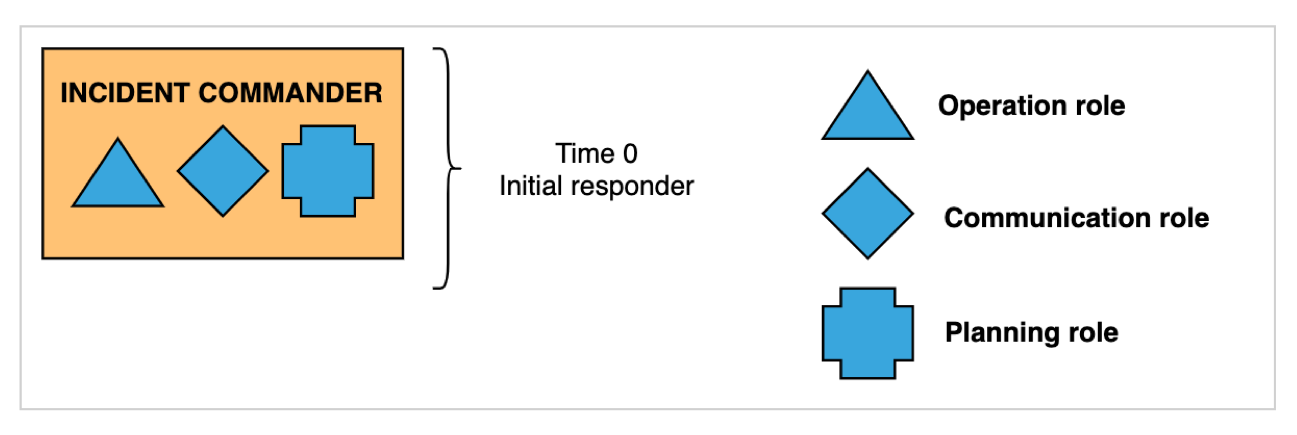
An incident is detected by an engineer and an incident response is triggered. We use chatops for triggering emergency responses - opening Zoom calls, Slack channels and alerting on-call engineers. The engineer that triggered the incident response (initial responder) assumes the IC role along with the OL, CL and PL role.
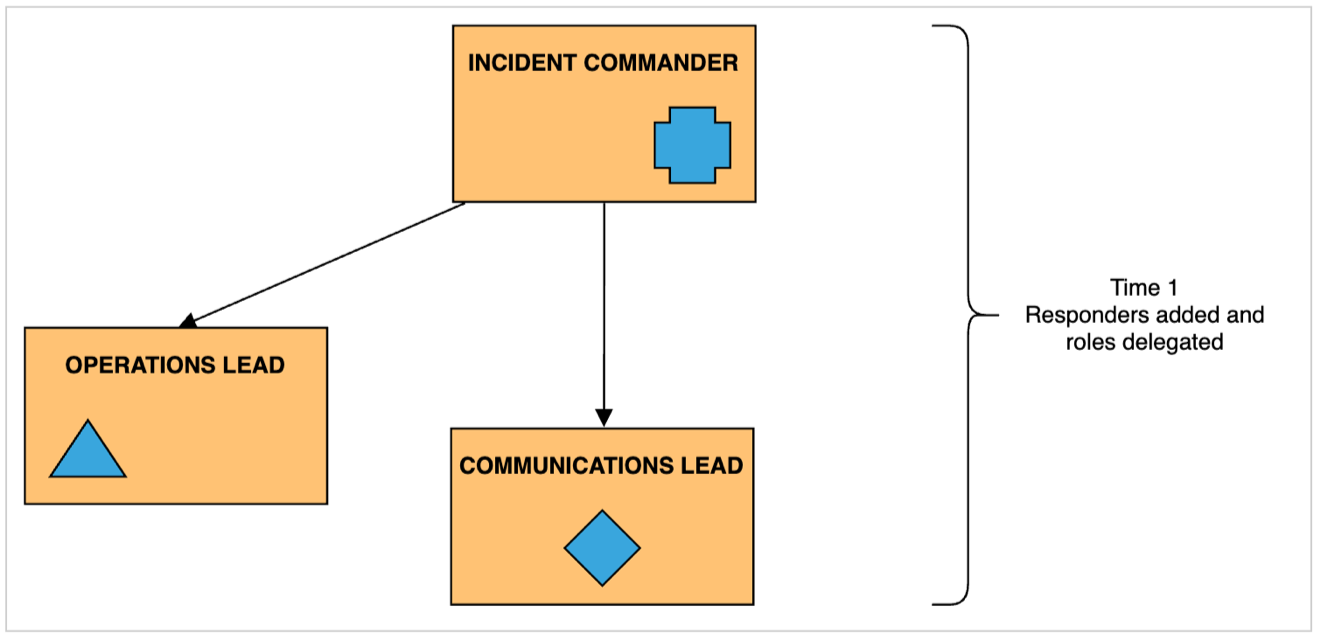
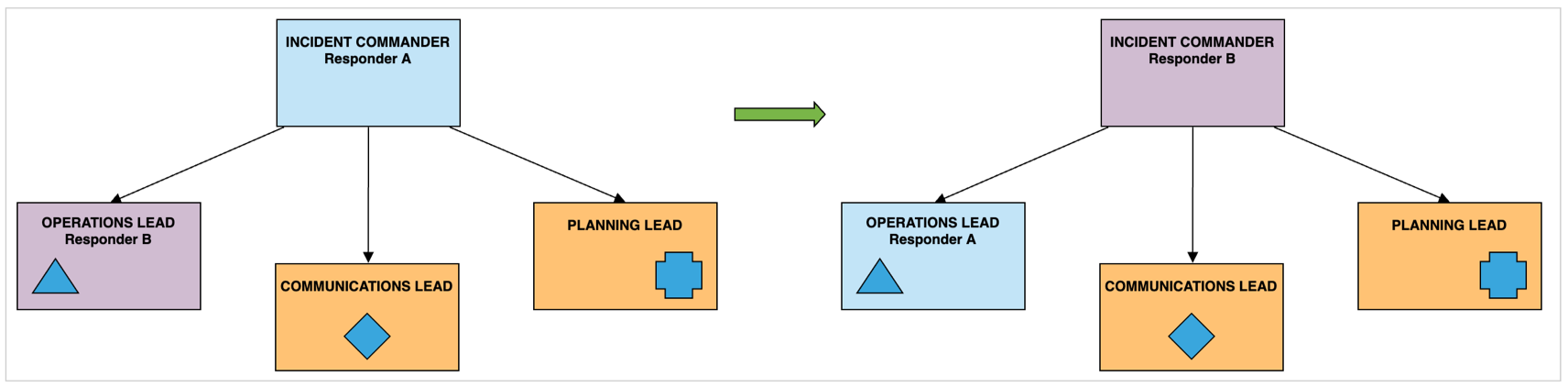
As responders join the incident the roles are delegated by the IC.
With larger incidents more engineers will be called in (by the PL). When problematic areas are identified we expand operational roles and create small teams to focus on these specific areas. These teams (in the picture below identified as database, trading, backend ops) leave main communication channels and join their own channels - this can be as easy as leaving the main Zoom call and going into a separate Zoom room. The OL periodically checks the status of the smaller teams and reports back to the IC. It is also a very good idea that each new team has its own scribe that updates the ISDs. We found that having junior engineers assume the scribe role works extremely well - they get to learn about how the platform works, yet they are not under stress as they are passively included in incident resolving.
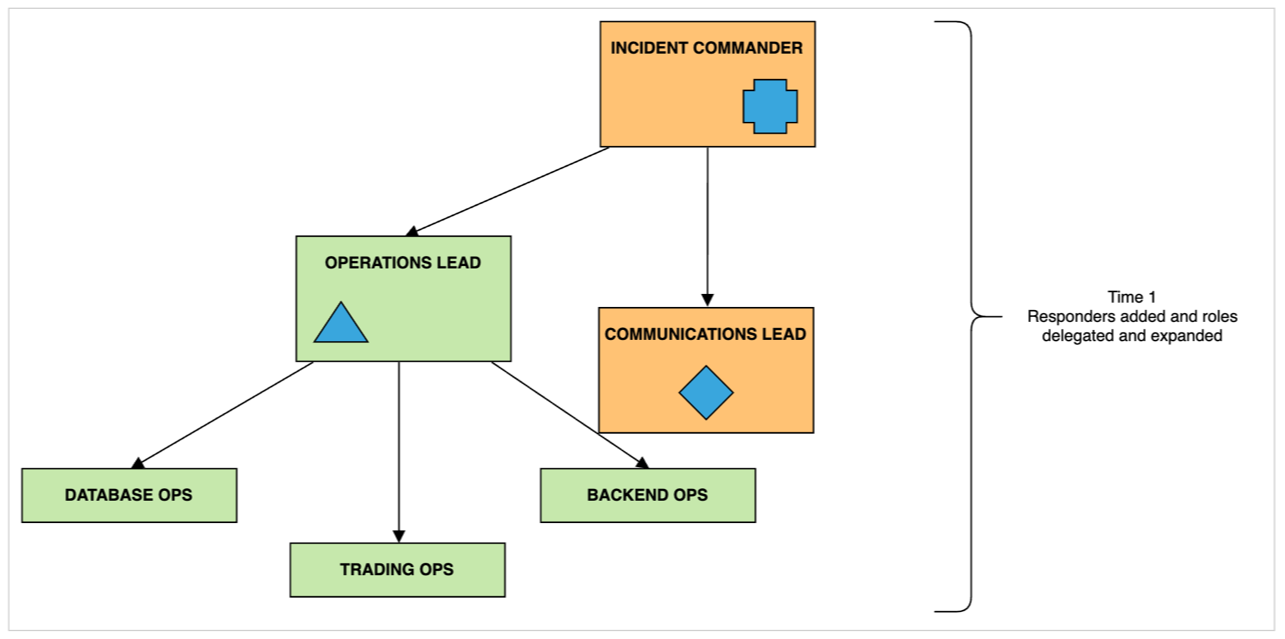
All roles can and should be switched. We all have areas where we excel at. Some responders have broader knowledge of the platform and can delegate tasks better, some responders are extremely efficient at specific problem solving. When we identify that there is a better use for responder's knowledge we switch or handoff roles.
Hopefully the incident is resolved soon and the teams of responders can be disbanded. We use the ISDs for the post mortem that follows. It is extremely important for us that we also discuss how the ICS performed and what were the identified flaws. From experience the main pain point will always be communication - as engineers we usually do not excel at communication, especially when we are in the middle of problem solving. How can we tackle "soft skill" issues? The answer is practice and a lot of it. We'll dive into our emergency response drills in the next article.
Credits
A lot of the ideas behind our Incident Command System are inspired by Alex Hidalgo's talk at LISA19 - Earthquakes, Forest Fires, and Your Next Production Incident. Take a peak over here to see Alex's other works.
About Bitstamp
Bitstamp is the world’s longest-running cryptocurrency exchange, supporting investors, traders and leading financial institutions since 2011. With a proven track record, cutting-edge market infrastructure and dedication to personal service with a human touch, Bitstamp’s secure and reliable trading venue is trusted by over four million customers worldwide. Whether it is through their intuitive web platform and mobile app or industry-leading APIs, Bitstamp is where crypto enters finance.
To join Bitstamp’s rapidly growing global team, visit Bitstamp Careers page and explore 40+ positions, including Systems Operations Engineer, Software Engineer, Infrastructure Engineer and more.